IMPORTXML関数でスプレッドシートにウェブページの情報を挿入する

IMPORTXML関数はスプレッドシートにウェブページの要素(データ)を挿入することができる関数です。
本記事ではIMPORTXML関数の使用方法について、画像を用いてできる限り分かりやすく使用方法を解説していきます!
まず、IMPORTXMLの“XML”とは、、、
XMLは、文章の見た目や構造を記述するためのマークアップ言語の一種です。 主にデータのやりとりや管理を簡単にする目的で使われ、記述形式がわかりやすいという特徴があります。
https://www.cybertech.co.jp/xml/contents/xmlxmldb/serial/_xmlbeginner1.php
つまり、IMPORTXML関数を使用するとウェブページなどの見た目や構造の情報を取得してそれらをスプレッドシートに表示することができるということです!
XMLは非IT系の方にとっては分かりにくいと思いますので、とにかくIMPORTXML関数を使用すれば、「ウェブ上からデータをスプレッドシートに挿入できる」とだけ考えていただいて問題ありません。
IMPORTXML関数を使用すれば以下のようなことができるようになります。
それでは、以下からはIMPORTXML関数の使用方法を解説していきます。
IMPORTXML関数の使用方法
IMPORTXML関数の使用方法を解説していきます!
IMPORTXML関数の構文
まず、IMPORTXML関数の構文は以下です。
IMPORTXML(URL, XPath クエリ)
IMPORTXML(“https://en.wikipedia.org/wiki/Moon_landing”, “//a/@href”)
IMPORTXML関数 ドキュメント エディタ ヘルプ
●URL
データを取得するウェブページのURLを記述します。
URLの値は””(ダブルコーテーション)で囲むか、適切なテキストを含むセルへの参照にする必要があります。
●XPath クエリ
構造化データで実行するXPath クエリを記述します。
XPath クエリの値は””(ダブルコーテーション)で囲むか、適切なテキストを含むセルへの参照にする必要があります。
XPath クエリとは、、、
XPath (XML Path Language)とは、XML形式の文書から、特定の部分を指定して抽出するための簡潔な構文(言語)です。
https://www.octoparse.jp/tutorial/xpath/
つまり、「ウェブページ上のどこに記述されているか」を明示するための言語がXPath クエリということです。
「でもXPath クエリなんてどうやって記述したら良いか分からない。。。」
そんな方も安心してください!
XPath クエリは簡単にデータ取得元のウェブサイトから取得することができますので、その方法についてもこれから解説していきます!
IMPORTXML関数の使用例
ここからは実際にIMPORTXML関数を使用した画像を交えながら、具体的に使用法を解説していきます。
もちろん、XPath クエリの取得方法についても解説いたします!
それでは解説していきます!
XPath クエリを取得する
まずはスプレッドシートに挿入したいデータが存在するウェブページを表示します。
今回は、本ブログの1つの記事を例として使用させていただきます。
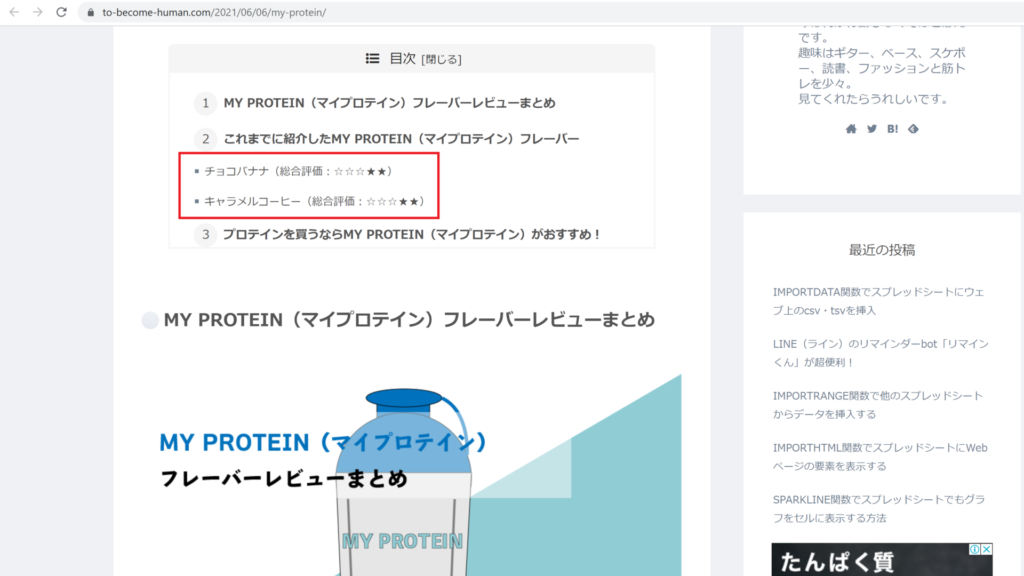
今回は上の画像の赤枠(目次の一部)のXPath クエリを取得してスプレッドシートに表示させます。
ウェブページを表示して、[F12]キーを押します。
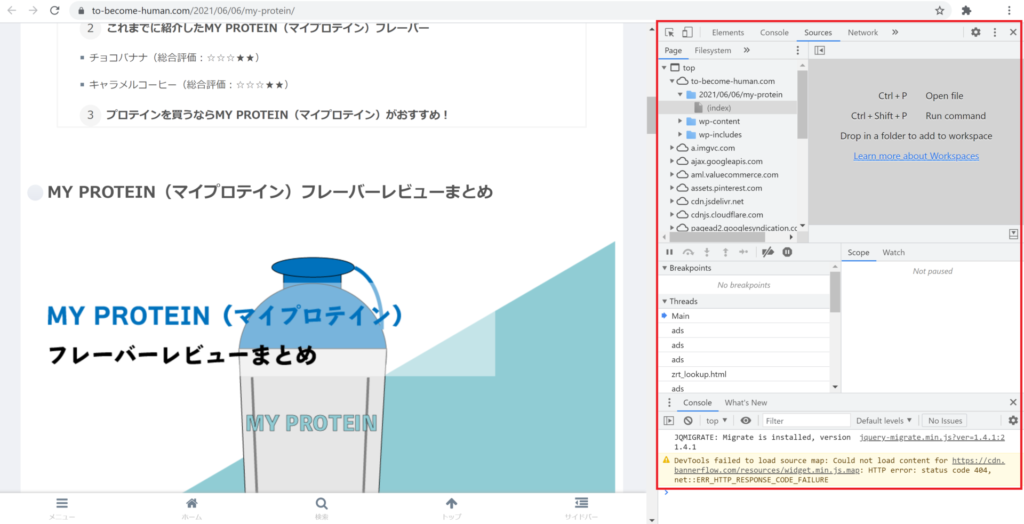
すると上の赤枠のように開発者コンソールが表示されます。
“なんだか難しそうな画面”が表示されましたが、ここでは簡単な操作しかしませんので、大丈夫です。
開発者コンソールの矢印(左上)ボタンをクリックします。
下の赤枠の矢印のボタンを押下すると、マウスカーソルでXpath クエリを取得したい要素(箇所)
を選択することができるようになります。
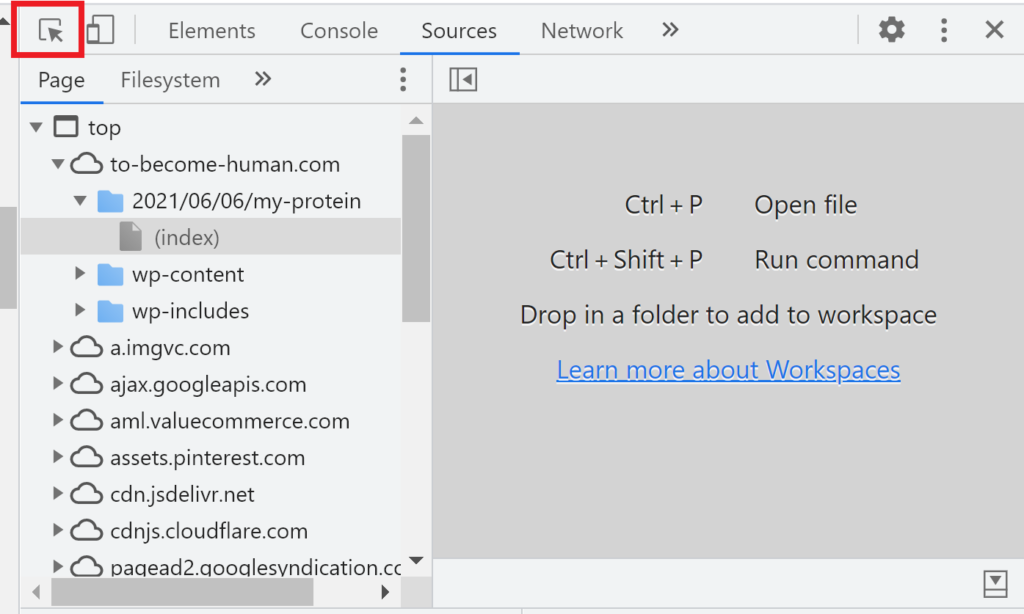
XPath クエリを取得する要素(箇所)を選択します。
マウスカーソルを取得したい要素に合わせると、色が変わります。
スプレッドシートに表示させたい箇所すべての色が変わったらクリックします。
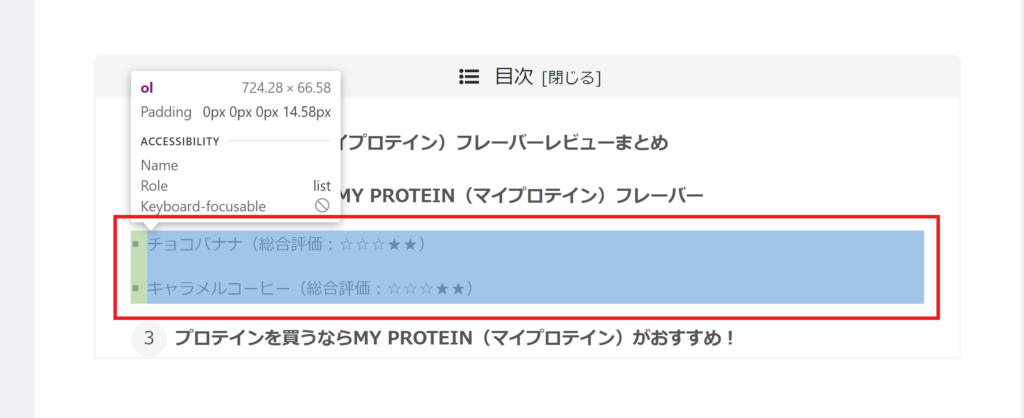
X Pathクエリをコピーします。
上の画像で表示させたい要素をクリックすると、コンソールに選択した部分のソースコード(表示させるための言語)が青色の背景で選択されます。
青色の背景に変わった部分を右クリックして、「Copy」>「Copy XPath」をクリックします。
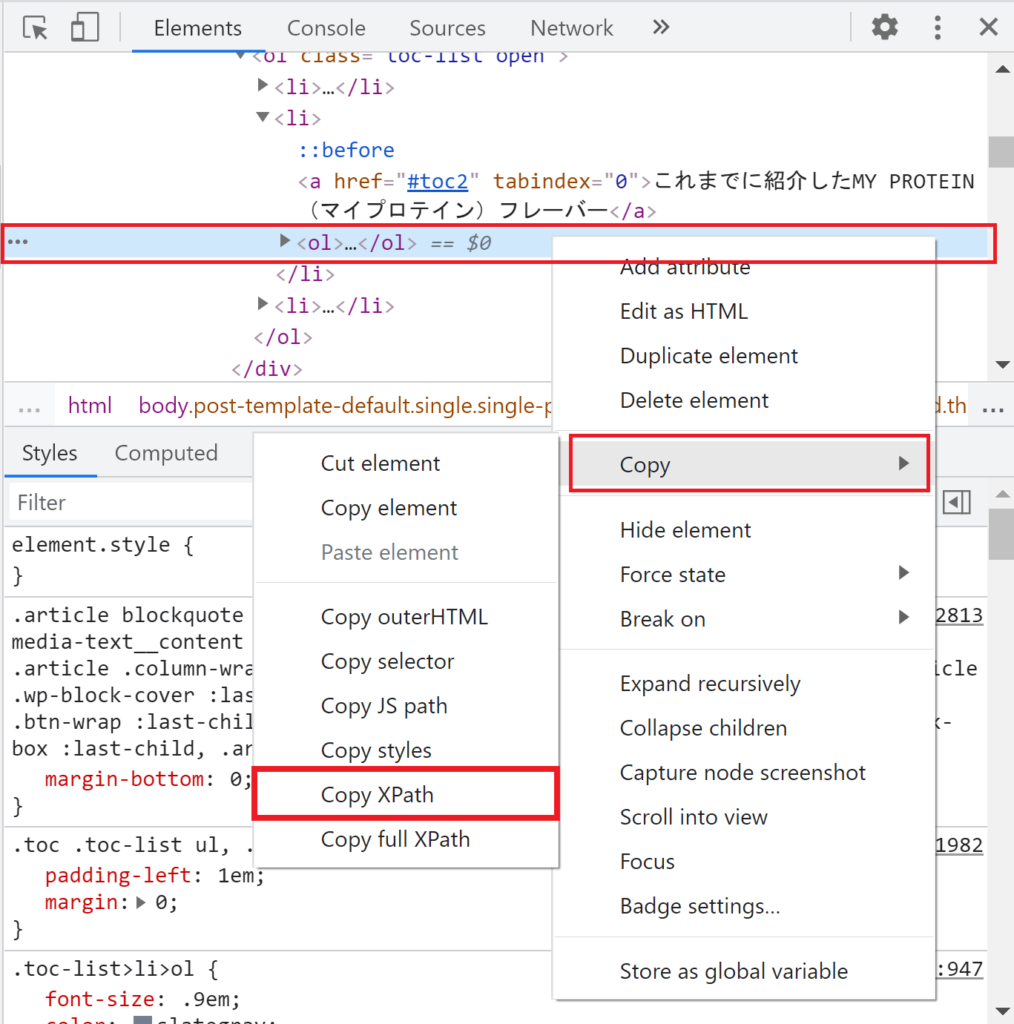
すると、表示させたい要素(データ)のXPath クエリが取得できます!
専門知識がなくても問題ないですよね?
それでは取得したXPath クエリを使用してスプレッドシートに取得した要素を挿入していきましょう。
スプレッドシートに表示します。
スプレッドシートの任意のセルに上のウェブページのURLと先ほど取得したXPath クエリをIMPORTXML関数に引数として記述していきます。
=IMPORTXML("https://to-become-human.com/2021/06/06/my-protein/","//*[@id="toc"]/div/ol/li[2]/ol")

[Enter]を押して、入力を完了すると。。。

“#ERROR”となってしまいます!
実は、XPath クエリはコピーしたそのままを貼り付けてしまうと、IMPORTXML関数ではエラーが出てしまいます。
そのため、XPath内の「toc」前後の“”(ダブルコーテーション)を”シングルコーテーションに変更する必要があります。
=IMPORTXML(“https://to-become-human.com/2021/06/06/my-protein/”,”//*[@id=‘toc‘]/div/ol/li[2]/ol”)

修正を完了して[Enter]を押すと。。。

取得したXPath クエリの要素がスプレッドシートに表示されました!
上記のような手順でXPathを取得して、IMPORTXML関数を使用することでスプレッドシートにウェブ上の要素を表示させることができます。
IMPORTXML関数その他の使用方法
上で紹介した使用例以外にもよく使用されるIMPORTXML関数の使用方法もいくつか紹介しておきます!
※ウェブページの構造次第ではうまく表示されない場合があります。
ウェブページのタイトルを表示
以下のようにIMPORTXML関数のXPath クエリ引数を記述することでウェブページのタイトルを取得可能です。
=IMPORTXML("URL","//title")

ウェブページのキーワードを表示
以下のように記述することでウェブページのキーワードも取得することができます。
ウェブマーケターの方であれば、競合のサイトのキーワード分析に使用も可能ですね!
=IMPORTXML("URL","//meta[@name='keywords']/@content")

ウェブページのディスクリプションを表示
ウェブページのディスクリプション(ページ概要)を表示させることも可能です。

IMPORTXML関数の使用上の注意点
IMPORTXML関数を使用する際にはいくつか注意点がありますので、それらについても触れておきます。
大手サイトでは使用できない
アマゾンなどの大手のサイトではXPath クエリが取得できないように対策がされている場合あり、IMPORTXML関数を使用してスプレッドシートに任意の要素が表示できません。
表示できないようであれば、コピペなどで転記するしかなさそうですね。。。
ウェブページの更新に依存する
ウェブページの情報が更新されるとスプレッドシートの内容が自動で更新されるのがIMPORTXML関数を使用してウェブ上の要素をスプレッドシートに表示するメリットですが、同時にデメリットにもなります。
例えば、ウェブページが消えてしまうと、スプレッドシートの情報も消えてしまいますし、ウェブ上の情報が間違っているとスプレッドシートの内容も間違った内容になってしまいます。
IMPORTXML関数で使用したデータは2時間毎に更新されるます。
たくさんの情報をウェブ上から挿入している場合は管理が大変なので、注意が必要です。
表示することができない要素がある
IMPORTXMLではウェブ上のすべての要素を表示できるわけではないので、注意です。
一度、上記で紹介した方法でXPathを取得してスプレッドシートでの表示を試してみて上手く表示されない場合はあまりIMPORTXML関数を使用することにこだわりすぎないようにしましょう。
特にウェブ上の表やリストであれば、過去の記事でも紹介しているIMPORTHTML関数を使用することをおすすめいたします。
まとめ:IMPORTXML関数でウェブ上のデータを挿入
ウェブページ上のデータをスプレッドシートに表示させるIMPORTXML関数について使用方法を解説いたしました!
IMPORTXML関数はExcelにはスプレッドシート独自の関数なので、スプレッドシートを使用するのであれば知っていて損はない関数です。
他のExcelにはなくてスプレッドシートには存在する便利な関数を下のリンクでまとめていますので、興味がある方はご覧ください!


に忙しい社会人が一発合格した効率的な勉強方法!-300x169.jpg)
に忙しい社会人が一発合格する効率的な勉強方法!-300x169.jpg)





コメント
コメント一覧 (1件)
[…] GOOGLEFINANCE関数は、グーグル自身が運営しているGOOGLFINANCEを有しているがゆえのExcelにはない独自の関数ですね。とても人気な米国株の多くはGOOGLEFINANCE関数でサポートされているので、自分のポートフォリオをスプレッドシートにまとめてみても面白いかもしれませんね!残念ながら日本株サポートされていないのですが、IMPORTXML関数を使用してYahooファイナンス等からスプレッドシートに挿入する方法もあるようなので、日本株もまとめてみたい方は調べてみてください!他のExcelにはないスプレッドシート独自の関数を下のリンクでまとめていますので、もし興味がある方はそちらもご覧ください。 […]