書類の電子化が進んでいる昨今ですが、まだまだ紙による書類のやり取りをしている企業も多くあるのではないでしょうか。
たくさんの紙の書類を目で見て管理している表に転記するような作業では、時間が掛かってしまったり、入力ミスが発生してしまうことも多くあるかと思います。
その紙書類からの転記作業、もしかしたらPower Automate Desktopを使って自動化できるかもしれませんよ!
OCR(Optical Character Recognition:光学文字認識)とは、手書きの文字や印刷の文字を読み取って、PCで利用できるような形式に変換してくれる技術のことです。
(参考:OCRとは|メディアドライブ)
Power AutomateはこのOCR機能が備えられており、それをなんと無料で使用することができます!
この記事では、Power AutomateでOCRを使用する方法を解説していきます。
当ブログでは、他にもPower Automateの活用方法をご紹介しておりますので、参考にしていただければ幸いです。
(参考:Power Automate活用事例)
OCRをする上での注意点
OCRは画像やPDFから文字を抽出する機能ですが、画質が悪いや、文字の大きさやフォントが異なるなどの理由で、正確に文字を抽出できないことがあります。
そのため、OCRを使用する場合は、画質の良い画像やPDFを使用するようにして、正確な結果を得るよう心がける必要があります。
当ブログでも、、OCRによって認識した結果が正しいことを保証する内容ではありませんので、実際に業務にて運用を開始する前に十分に期待通りの結果が出るかを検証するようにしてください。
また、すべてをRPAにまかせるのではなく、処理結果に誤りがないことを確認ができるようなチェック体制を確立しておくようにしましょう。
Power AutomateでOCRを使用する方法
Power Automateを使用する際には、いくつかのオプションがあるので、選択できる検索モードの3つに分けて解説をしていきます。
また、OCRエンジンもいくつか選ぶことができますが、日本語の認識が可能な「Windows OCR エンジン」を使用します。
他にも、「Tesseract エンジン」というOCRエンジンも用意されていますが、こちらで日本語で認識させるためには、設定を変更させる必要があるので、今回は何もせずに日本語を読み取ることができる「Windows OCS エンジン」を使用します。
Power Automateで簡単フローの作成は理解していることを前提に説明をしていきますので、まだ自信がないという方は以下の記事で基本的な使用法を含めて丁寧に解説していますので、参考にしながら読み進めていただければと思います。
(参考:Power Automateの基本的な操作方法)
それでは、Power AutomateでOCRを使用する方法を解説していきます。
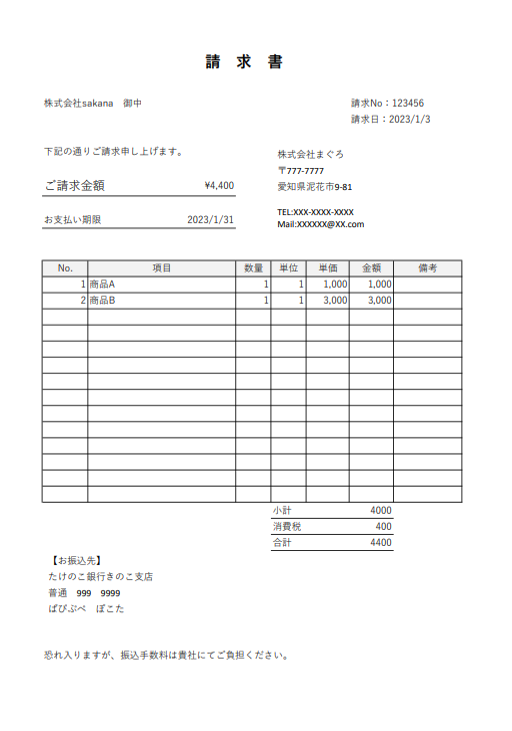
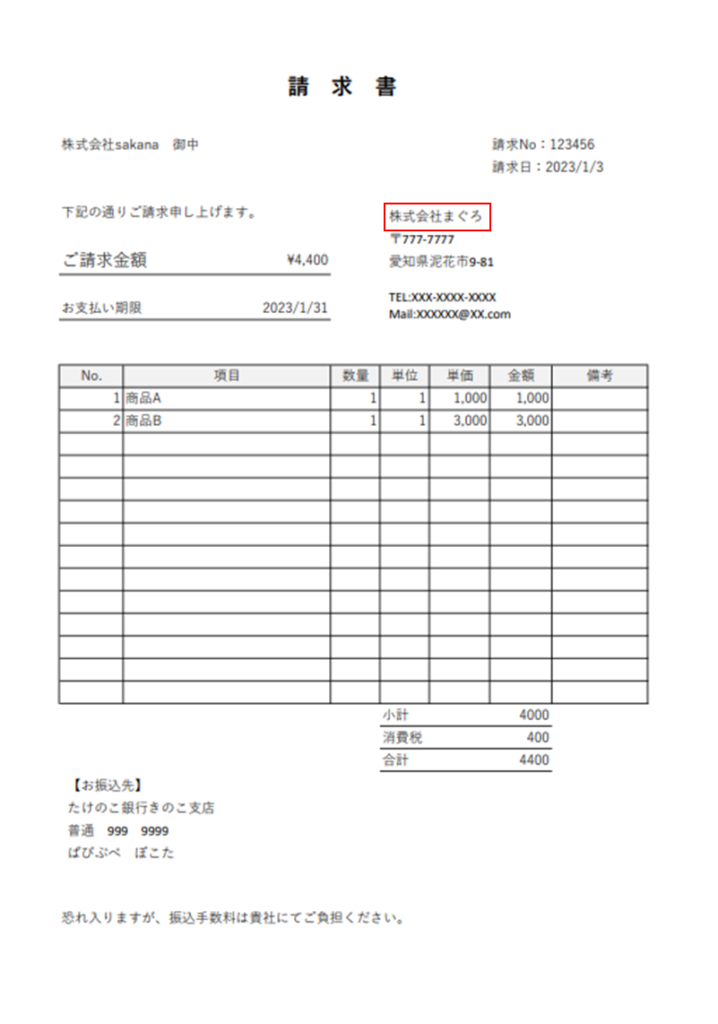
今回は以下のような請求書の画像を例に文字列を抽出していきます。
以下では、いずれもアクションの中から「OCRを使ってテキストを抽出」をフローに追加します。


指定されたすべてのソース
まずは、選択した画像上のすべての文字列を抽出する検索モード「指定されたすべてのソース」の手順を解説していきます。
Wordなどのような連続しているすべての文字列を抽出したい場合に使用すると良いでしょう。
少し、用途には合わないかもしれませんが、上の例の請求書のすべての文字列をこの検索モードで抽出してみます。
「OCRを使ってテキストを抽出」をフローに追加すると、設定ダイアログが表示されますので、検索モードを「指定されたすべてのソース」を選択します。
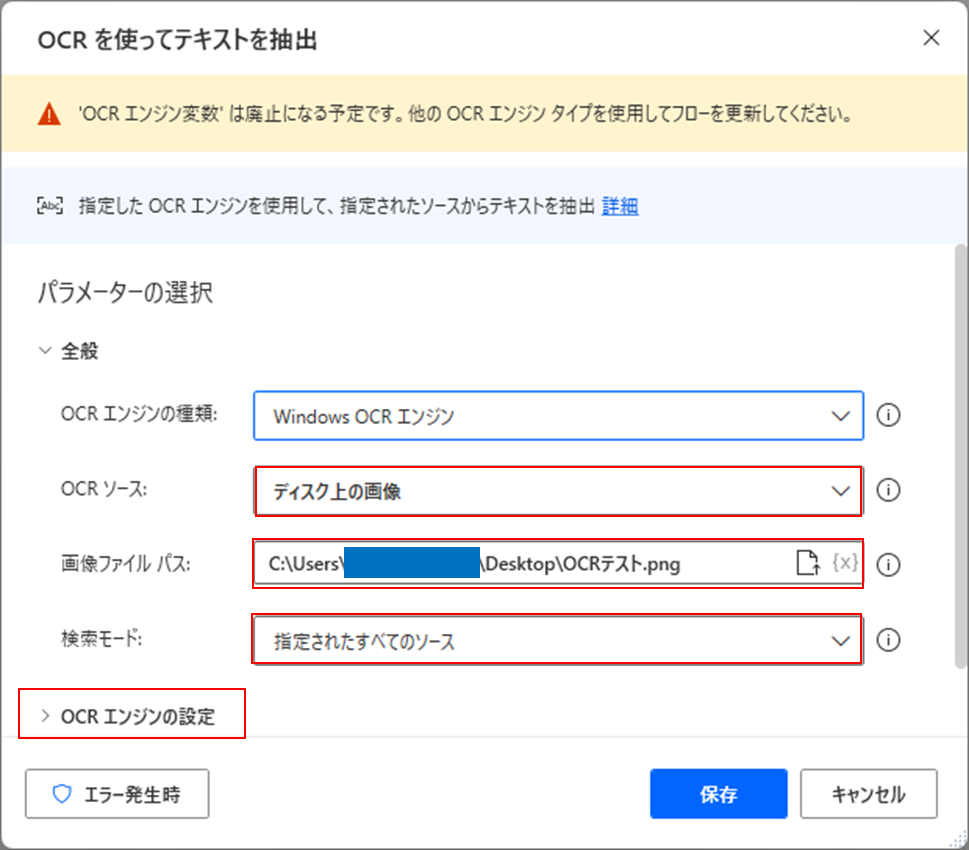
また、今回は保存された画像から文字を認識させるため、OCRソースを「ディスク上の画像」とし、対象の画像のファイルパスを指定します。
ファイルパスには変数を指定することもできますので、処理の中で動的にファイルパスを変えたい場合には、変数を使うと良いでしょう。
変数は少しプログラミング的な考え方なので、以下の記事でPower Automateを題材として解説していますので、変数が何か分からない方はご参照ください。
(参考:Power Automateを題材に変数を解説)
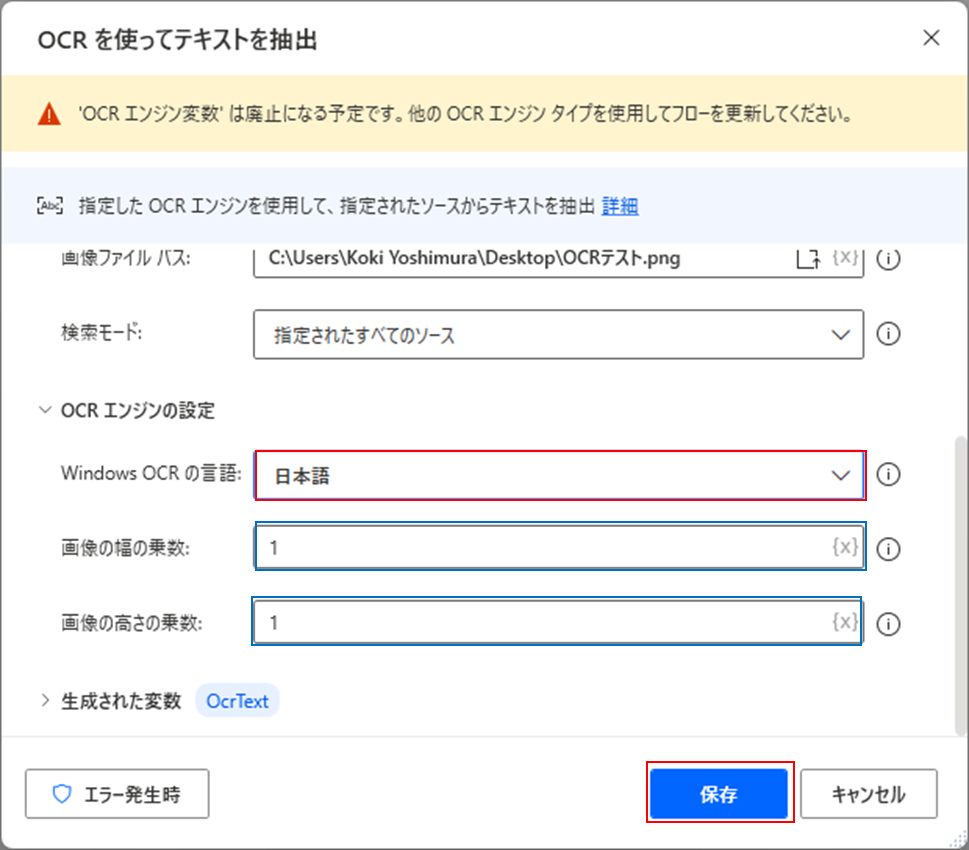
他にもOCRの設定をするために、「OCRエンジンの設定」をクリックして詳細な設定メニューを開きます。
以下のようにWindows OCRの言語を「日本語」に設定し、画像の幅(高さ)の乗数を任意の値に設定して「保存」をクリックします。
Microsoft公式によると、画像の幅(高さ)の乗数については、以下の通り解説されています。
画像の乗数は画像のサイズを大きくし、テキストの抽出や検索をより効果的におこなえるようにします。 3 より大きい値を設定すると、誤った結果が生じる可能性があることに注意してください。
(参照:OCR – Power Automate | Microsoft Learn)
以下のようにファイルにOCRで抽出したテキストを書き込むフローを追加して、このフローを実行した結果を確認してみます。
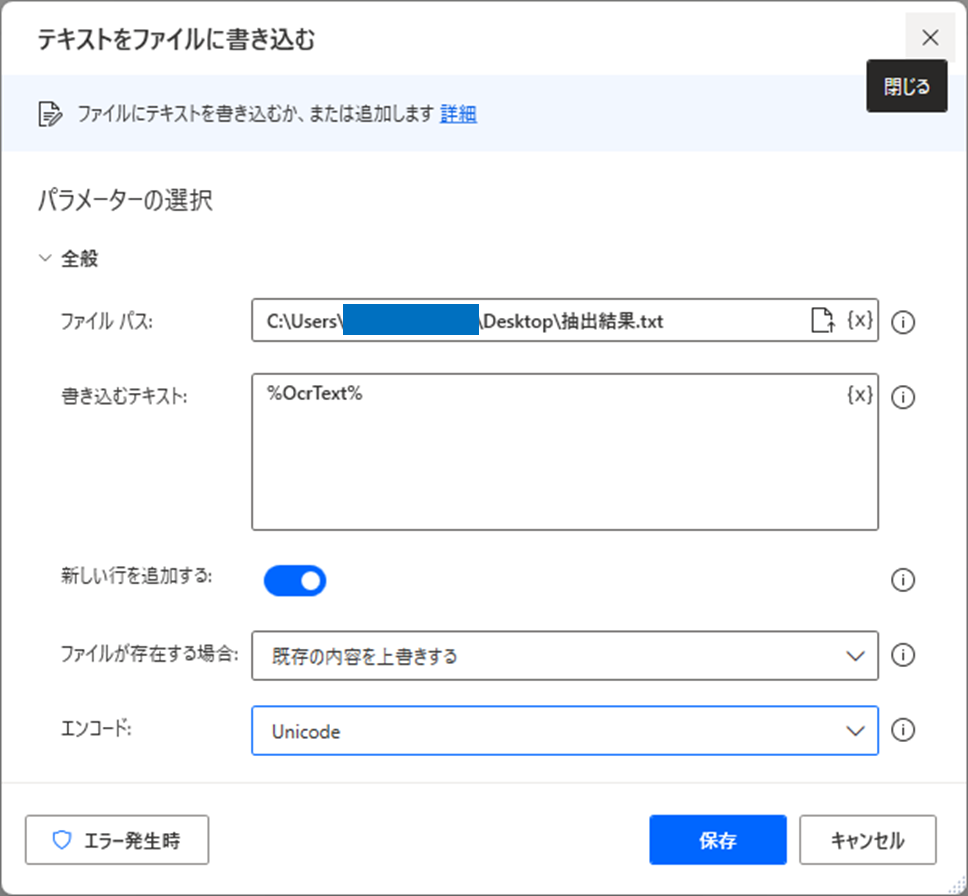
フローを実行した結果は以下の通りです。
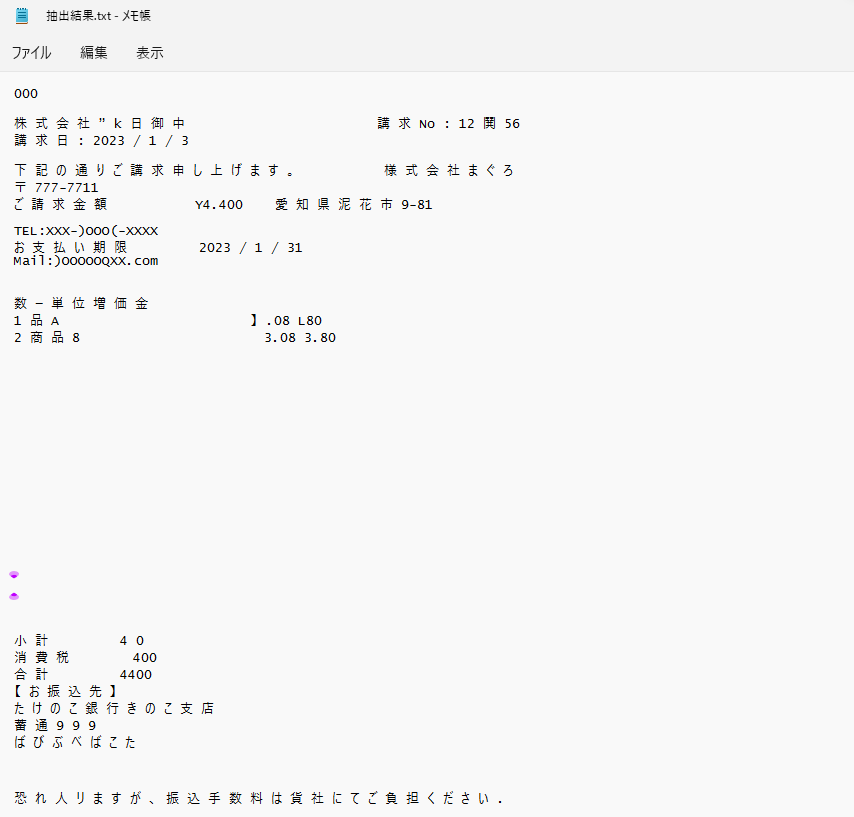
レイアウトが複雑なこともあって、結果はかなりめちゃくちゃですね。。。
リアルな結果として、参考にしていただけると幸いです。
特定のサブ領域のみ
今度は、指定した範囲内の文字列を抽出する検索モード「特定のサブ領域のみ」を解説します。
この「特定のサブ領域のみ」は、取得したい文字列が必ず画面上の決まった場所に表示される場合に有効な検索モードです。
先ほどの請求書サンプルの赤枠の会社名を取得するOCRを例に挙げて説明していきます。
今回は範囲を指定するため、画像ファイルを一度開いて表示させるためにアクション「アプリケーションの実行」を以下のように対象の画像を開くように実行します。
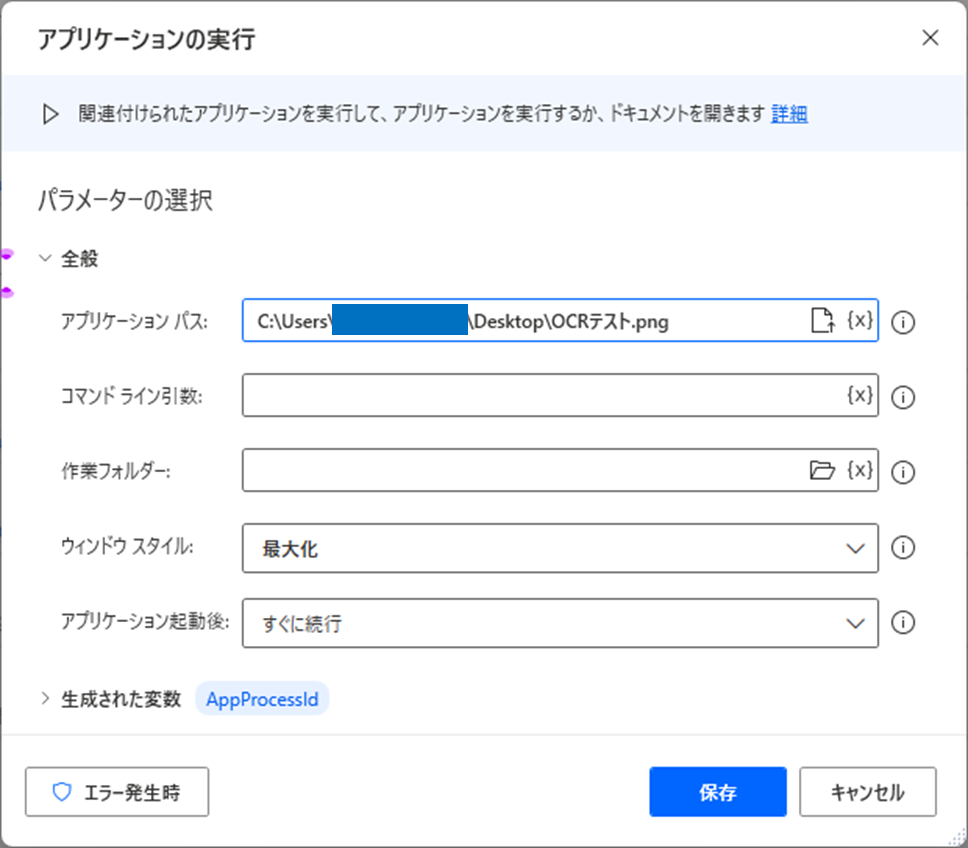
上のアクションを実行すると以下のように画像が表示されます。

アクション「OCRを使ってテキストを抽出」で表示されている画面の座標から文字列を抽出するために、OCRソースを「フォアグラウンド ウィンドウ」を選択して座標(幅,高さ)の始点(X1,Y2)と終点(X2,Y2)を指定します。
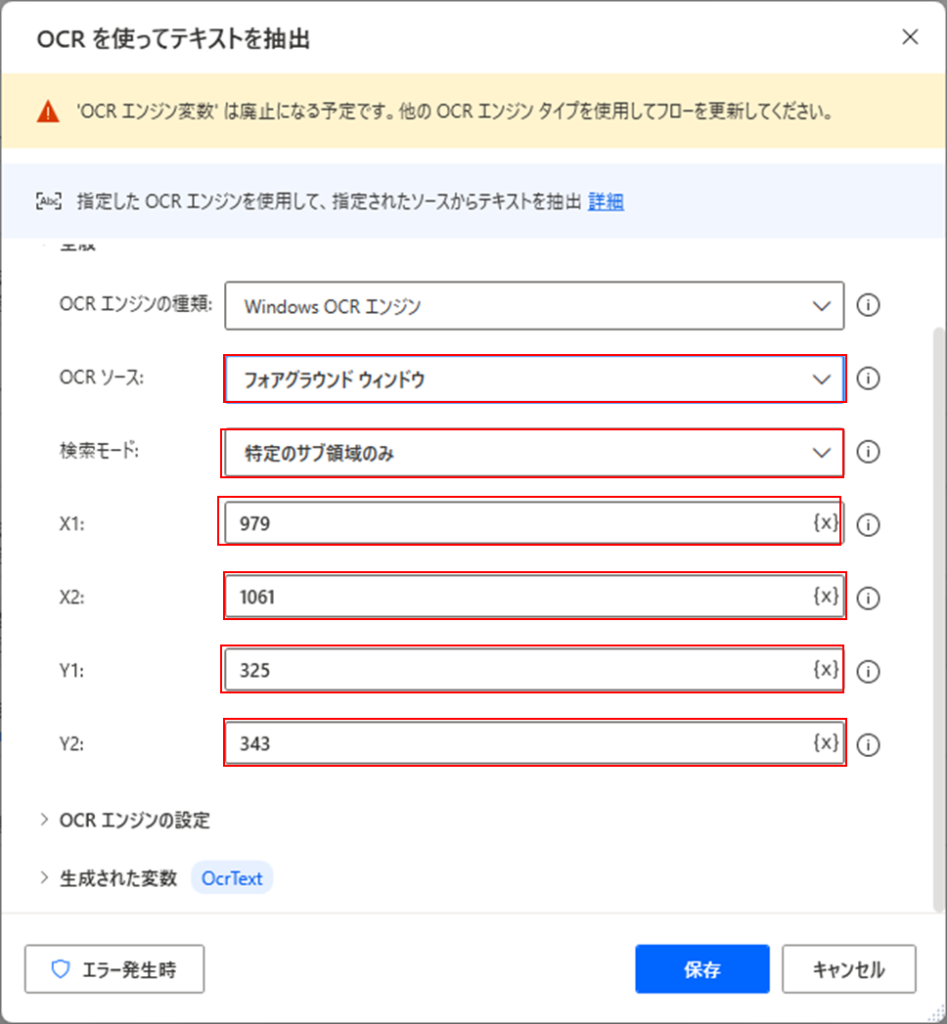
今回の例の場合は、以下のように範囲を取得しています。
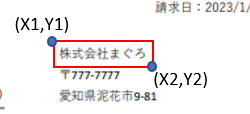
座標の取得は少し面倒なのですが、以下のサイトを参考に座標を参考にしたり、ツールを使う方法があります。
(参考:マウス座標位置、スクロール量、ウインドサイズなどを取得する)
また、私の場合は上手く取得ができなかったので、Power Automateのアクション「マウスの位置を取得します」を使ってコツコツと取得しました。。。
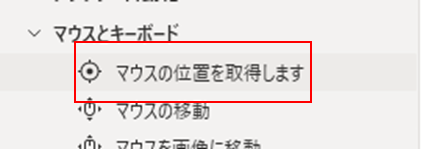
「特定のサブ領域のみ」をOCRするために作成したフローは以下のようになりました。(画像を開いた後に確実に認識させるために「Wait(待機)」を5秒入れています。)
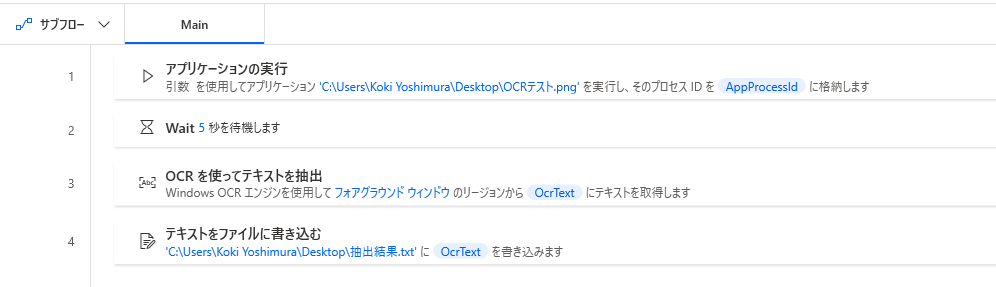
実際にフローを実行してみると以下のようになります。
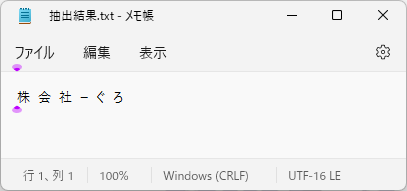
相変わらず実行結果は安定しませんね。。。
画像に対するサブ領域の相対値
検索モード「画像に対するサブ領域の相対値」はまず、あらかじめ画像上の変わらない部分を指定して、指定した部分を基準として、OCRして文字列を抽出する検索方法です。
位置は固定ではないが、必ず決まった画像が認識する対象に含まれており、その画像と相対的に流動的な情報が含まれている場合に役に立ちそうです。
例えば、今回の例では「ご請求金額」の右隣に金額が入力されるようなフォーマットになっています。
そのため、「ご請求金額」を基準にして、金額を抽出するようなOCRの処理をしてみます。

以下のようにOCRソースを「フォアグラウンド ウィンドウ」を選択し、「画像に対するサブ領域の相対値」を選択します。
すると、「画像を選択してください」が表示されるので、クリックします。
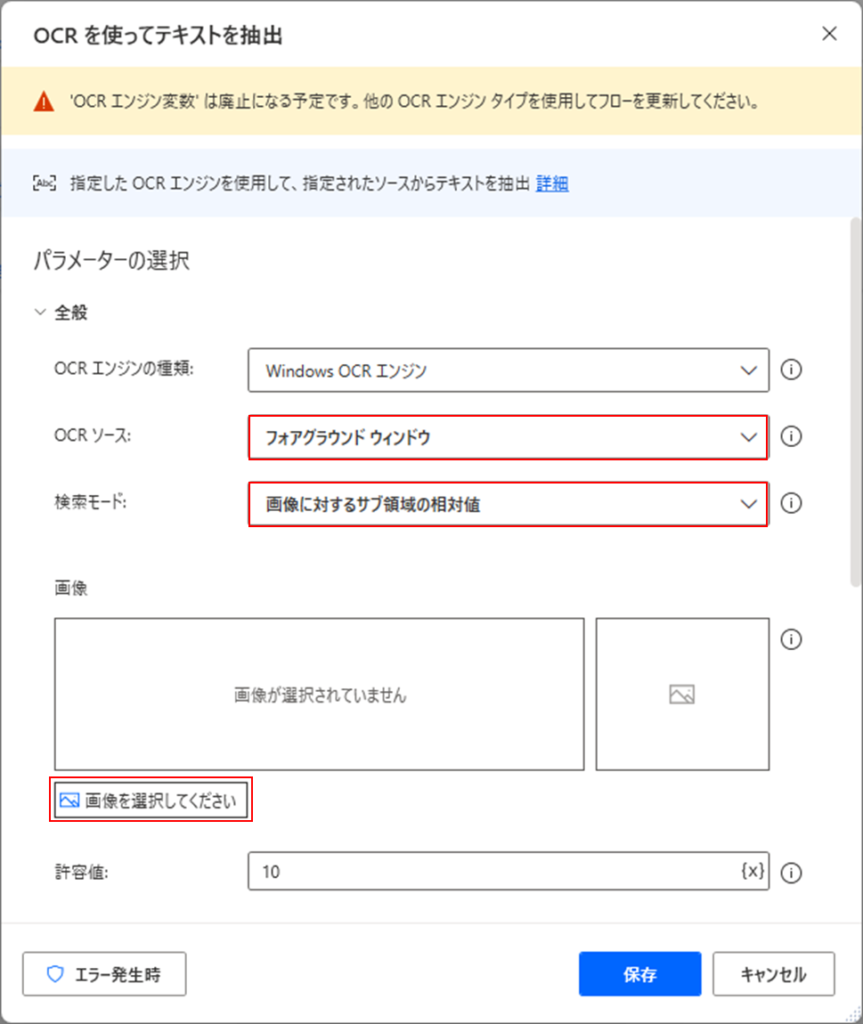
以下の画面が表示されるので、「画面のキャプチャ」をクリックします。
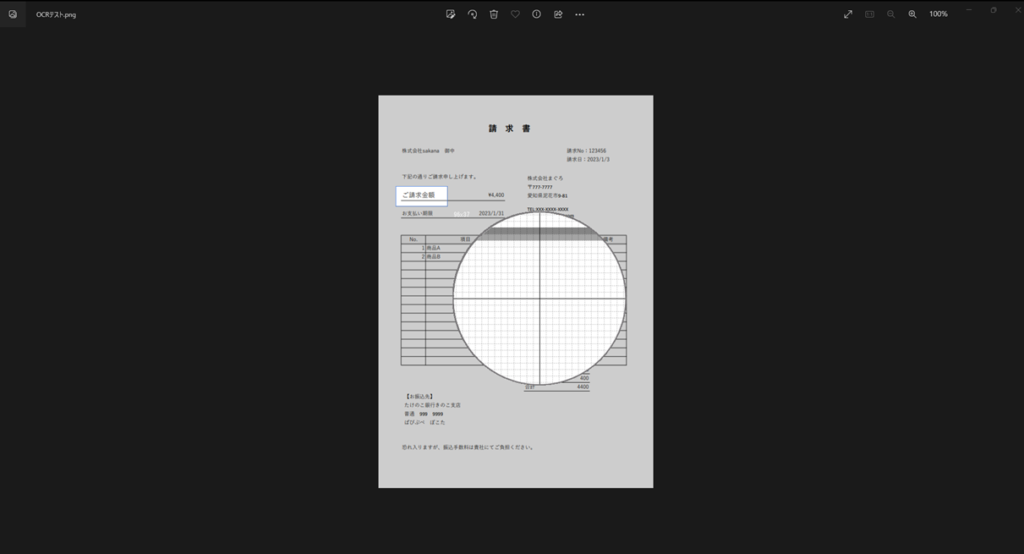
基準となる画像の箇所を範囲選択します。
基準となる画像の名前を付ける画面が表示されるので、任意の名前を付けて、「OK」をクリックします。
指定した画像から許容値と相対的な座標(X,Y)を指定していきます。(今度は大体の当たりを付けて適当に数値を設定しました。)
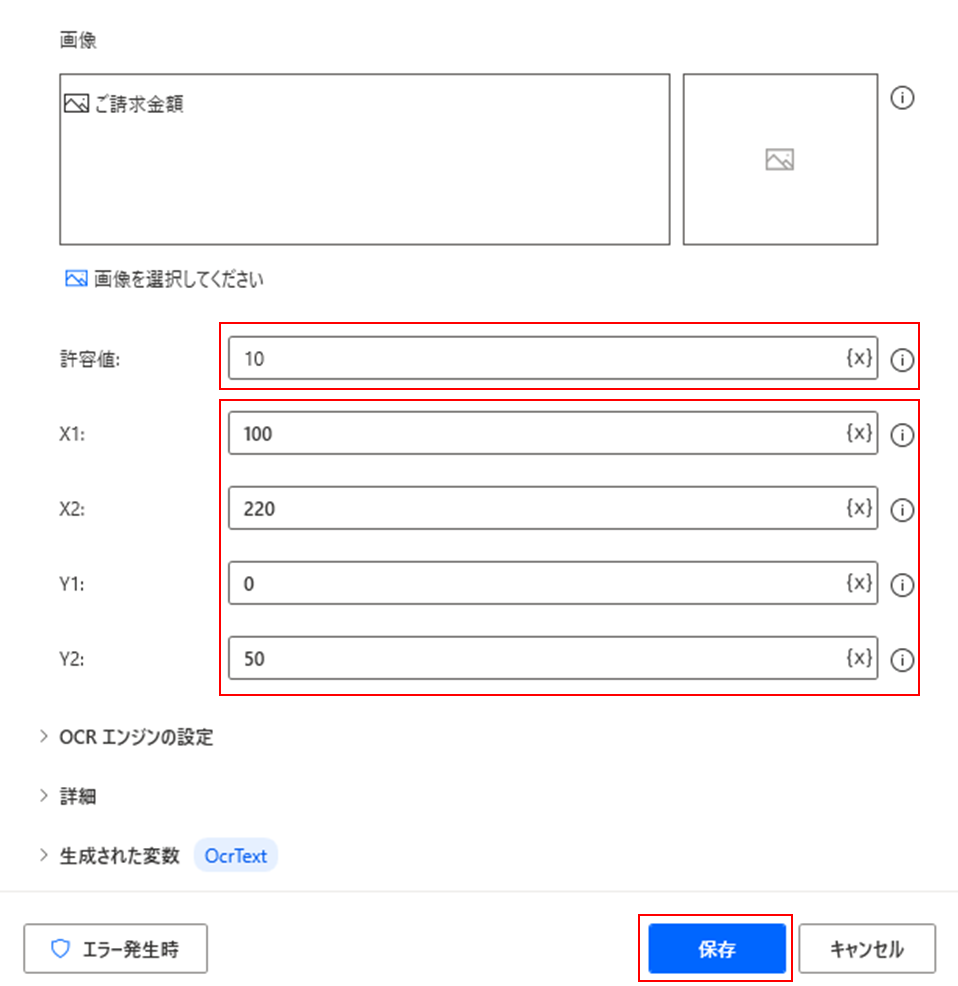
ここで設定される「許容値」は、基準となる画像がどれほど正確であるかを許容するかを指定します。
デフォルトで10が設定されますが、値が小さくなればなるほど基準として指定した画像と正確に一致しているかを厳しく判定するようになります。
基準となる画像に一致しないと判定された場合には、以下のようにエラーが出る場合がありますので、何度かテストを実施して許容値を設定するようにしましょう。

ここまでで作成したフローは以下の通りとなります。
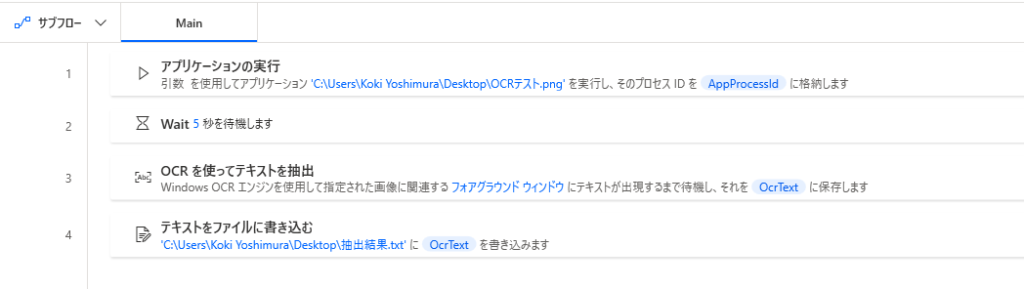
実行した結果は以下の通りとなります。
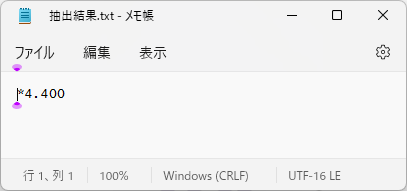
「\」が上手く表示されないのが、非常に惜しいですね。。。
予想ですが、文字認識結果を日本語に優先的に変換するようになっているため、記号等は苦手なのかもしれませんね。
まとめ:Power AutomateのOCRで文字列を抽出
今回はPower Automateを使ってOCRで文字列を抽出する方法を紹介しました。
以前、解説したフォルダ内のファイルすべてに対して同じ処理をするフローと組み合わせると、フォルダ内に存在する画像すべてに対してOCR処理をするなんてこともできそうですね。
(参考:Power Automateでフォルダ内のすべてのファイルに処理を実行する)
しかし、上記の結果を見て、「全然文字認識してくれないじゃん」と感じた方がきっと多いでしょうね。。。
無償で提供されるエンジンではまだこんなものなのかもしれませんが、限定的な使用方法であれば、何とか使えそうなのではないでしょうか。
「windows OCR エンジン」では、冒頭の注意点でお伝えしたようにOCRの精度に不安があるため、実際に運用を開始する前にしっかりとテストをして、チェックができる体制にしておきましょう!
当ブログでは、他にもPC関連の業務効率化テクニックを紹介していますので、興味がある方はぜひご覧いただけると幸いです。
(参考:PC関連の業務効率化テクニック一覧)

に忙しい社会人が一発合格した効率的な勉強方法!-300x169.jpg)
に忙しい社会人が一発合格する効率的な勉強方法!-300x169.jpg)





コメント