仕事をしていく上で、検索をして必要な情報を集めることはよくあることかと思いますが、様々なサイトが趣向を凝らした外観にしている中、必要な情報を目で見て取得していくのは意外に時間が掛かりますよね。
Power Automate Desktopは、デスクトップアプリケーションやWebサイトを自動操作することができるため、スクレイピングを行うこともできます。
スクレイピングとは、Webサイトからデータを収集することを指します。
今回は、Power Automateデスクトップを使用した簡単なデータスクレイピングを自動で行うフローの作成を行います!
当ブログでは、Power Automateデスクトップを活用した自動化の例を過去にも紹介してますので、興味がある方はそちらもぜひご覧ください。
(参考:Power Automate活用事例)
データスクレイピングをする際の注意点
Power Automateを利用してデータスクレイピングすることで、Webサイト上から自動で大量のデータを収集することが可能です。
便利な反面、スクレイピングをする前に注意をしておかなければいけないことがいくつかありますので、まずはそれらからお伝えいたします。
スクレイピングをするWebサイトの規約や利用条件を確認する

スクレイピングをするWebサイトによっては、スクレイピングを禁止、または、スクレイピングを許可する場合でも、利用条件や制限があることもあります。
スクレイピングをする前に、Webサイトの規約や利用条件を確認して、対象のWebサイトではスクレイピングが許可されているかを確認するようにしましょう。
また、Webサイトによっては、「robots.txt」というロボットによるページのクローリングを許可するかを記述したファイルを配置しているサイトもあるため、そちらも確認するようにしましょう。
- Webブラウザを起動します。
- アドレスバーに、以下のURLを入力します。 http://[Webサイトのドメイン]/robots.txt
- Enterキーを押すと、Webサイトのrobots.txtが表示されます。
「robots.txt」が存在する場合の記述の例としては、以下のように表示されます。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php「User-agent:」の後ろには、制限するクローラーが記述されます。
上の例では、*(アスタリスク)が記述されており、すべてのクローラーの種類が制限の対象となります。
「Disallow:」の後ろには、クロールを許可しないサイト、「Allow:」の後ろには、クロールを許可しないサイトが記載されます。
なお、Webサイトによっては、robots.txtが存在しない場合もあります。
その場合は、Webブラウザに「404 File Not Found」のようにファイルが存在しない旨を意味するエラーが表示されるか、空の画面が表示されます。
「robots.txt」内の記述については、以下により詳細に記載されておりますので、参考にしてみてください。
(参考:robots.txt の書き方、設定と送信方法)

スクレイピングをするデータの内容を確認する

RPAによってスクレイピングをする際には、人間の目を通して情報を収集して来てしまうため、データの内容を見て取捨選択することが難しいです。
そのため、収集するデータの内容を確認することが重要です。
特に、個人情報や機密情報を含むデータの場合は、法的に問題がある場合がありますので注意する必要があります。
スクレイピングをする前に、収集するデータの内容を確認し、問題がある場合は、スクレイピングを行わないことをおすすめします。
スクレイピングするデータの量を検討する

スクレイピングをする際には、収集するデータの量が大きくなることがあります。
ロボットによって機械的にデータを取得し続けるため、データがある限りデータ収集処理を進めてしまうと処理しきれないほどの不要なデータを集めてしまったり、Webサイトに多大な負荷をかける場合があるため、注意が必要です。
スクレイピングをする前に、収集するデータの量を検討し、必要なデータだけを収集するようにすることをおすすめいたします。
また、大量のデータを収集する場合は、スクレイピングを定期的に行うなど、頻度を考慮してWebサイトに負荷をかけずにデータを収集するのも1つの方法となります。
Power Automate Desktopでスクレイピングをする手順
注意点が長くなってしまいましたが、続いてPower Automate Desktopを使用してデータスクレイピングをする手順を解説していきます。
今回の例では、当ブログのトップページの記事一覧から「タイトル」と「説明文」を抽出して、Excelに出力するまでをフローにして自動化していきます。
Power Automateの基本的な使用方法は理解していることを前提に説明を進めていきますので、操作に自身が無いという方は、以下の記事で基本的な使い方から丁寧に解説していますので、参考にしてみてください。
(参考:Power Automateの基本的に使用方法)
では、早速新しいフローを作成する画面から解説を初めていきます!
Webブラウザの起動
まずは、Webブラウザを起動するフローを作成します。
「ブラウザー自動化」の中から起動したいブラウザの起動を選びます。
今回の例では、「新しいMicrosoft Edgeを起動」を選びます。
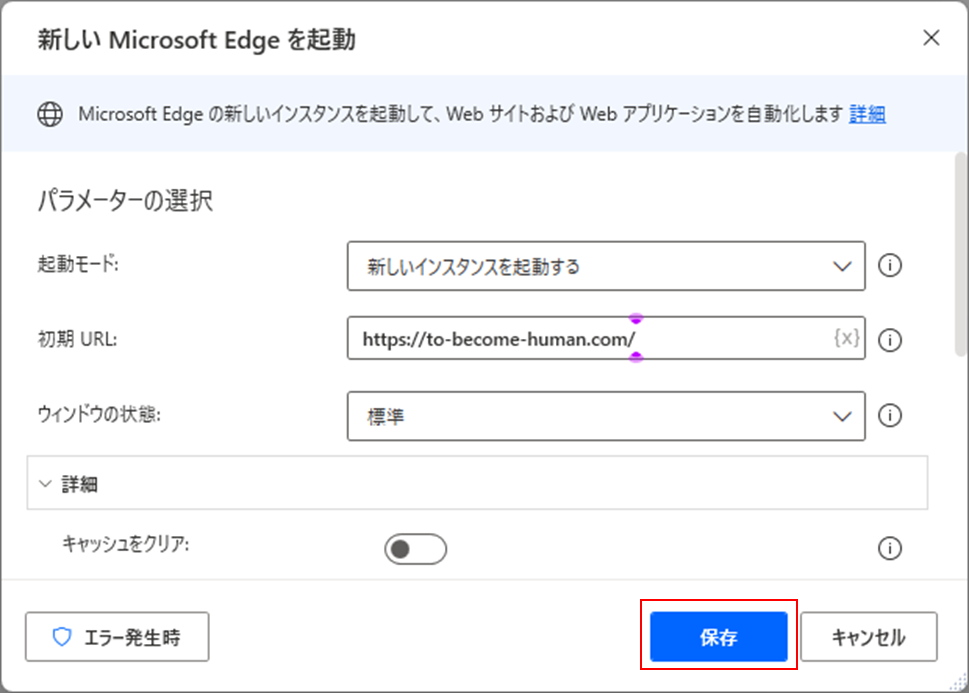
「初期設定URL」に、対象のWebサイトのURLを入力します。
今回は当ブログのURLを設定して「保存」します。
一度、設定した以下のフローを実行しておきましょう。

すると以下のように指定したブラウザで、設定したURLのサイトが表示されます。
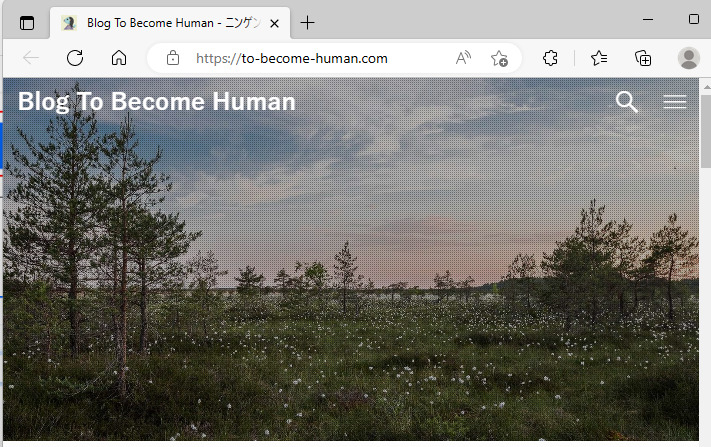
続いての手順で必要となりますので、ここで開いたブラウザはそのままにしておいてください。
Webページからデータを抽出する
続いて、このフローの肝となるWebページからデータを抽出する処理を設定していきます。
「ブラウザー自動化」から「Webページからデータを抽出する」を選んで、フローに追加します。
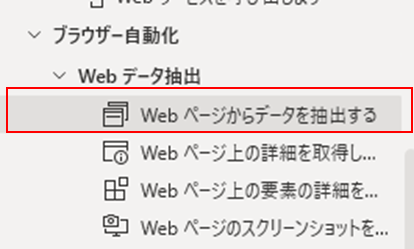
フローに追加をすると、以下のようなダイアログが表示されますので、「データ保存モード」を「Excelスプレッドシート」に設定します。
そして、このままにして先ほど開いていたブラウザに戻ってください。
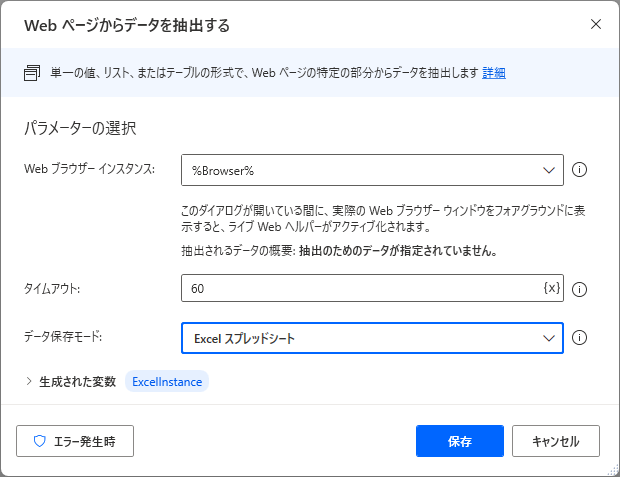
上の画像のまま「保存」を押してしまうと「パラメーター’抽出パラメーター’:空にできません。」というエラーが出てしまい、設定ができません。

ブラウザに戻ると、「ライブWebヘルパー」というポップアップが表示されます。
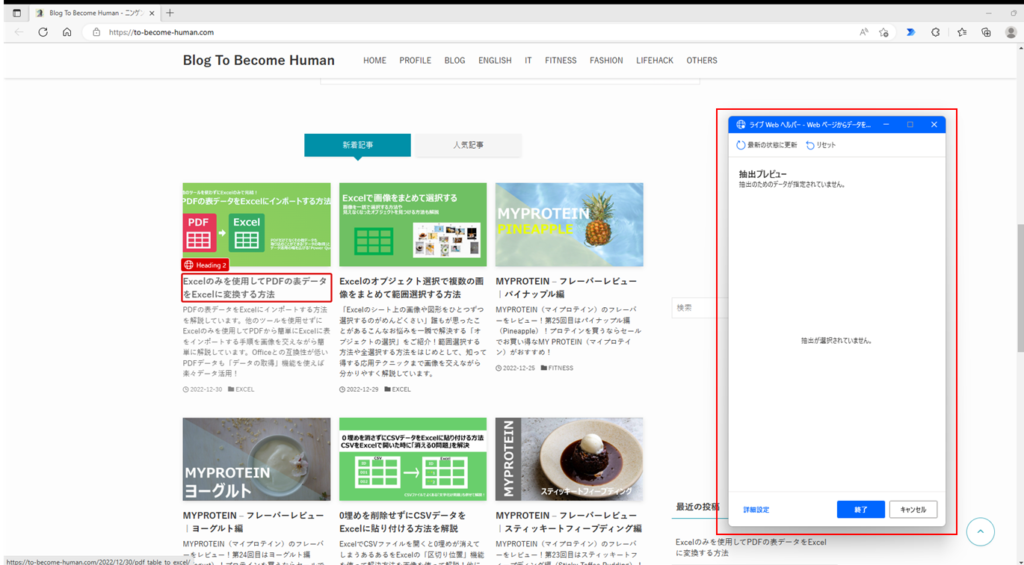
要素の抽出
ライブWebヘルパーの画面でスクレイピングによって収集するデータの要素を選択していきます。
まずは、記事一覧のタイトルを取得します。
記事一覧のタイトルにカーソルを合わせて、赤枠が表示されたら右クリックをして、「要素の値を抽出」>「テキスト」をクリックします。
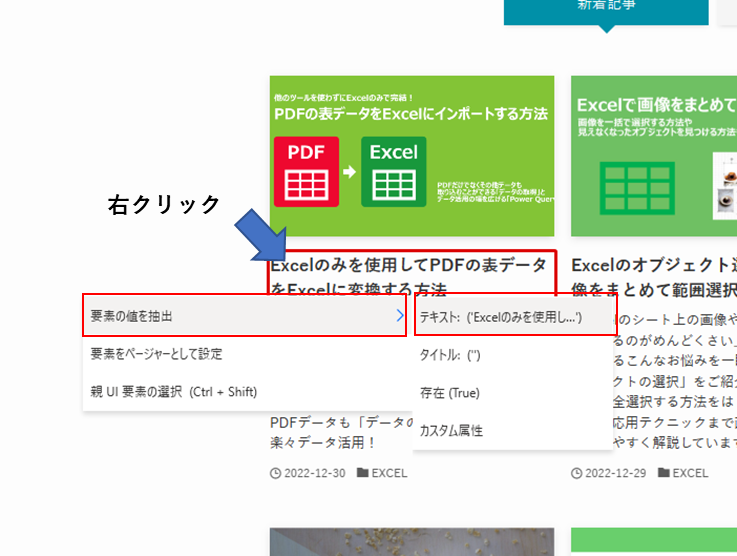
続いて、もう1つ隣の記事のタイトルも同様に要素として設定をします。
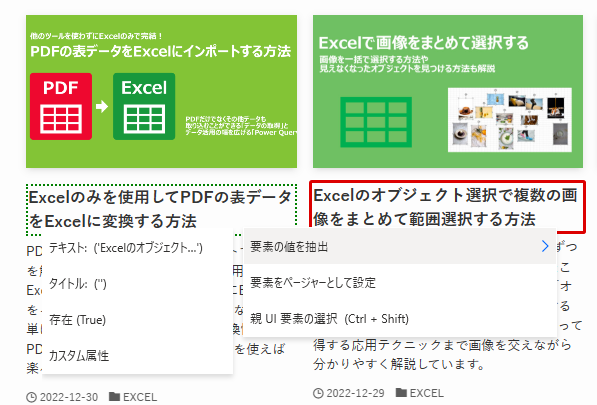
すると、ページに表示されている記事のタイトルの一覧がライブWebヘルパーに表示されました。

続いて、別の要素として記事の説明文を取得していきます。
今度は、ページの説明文が記載された箇所にカーソル合わせて同様に要素を取得します。
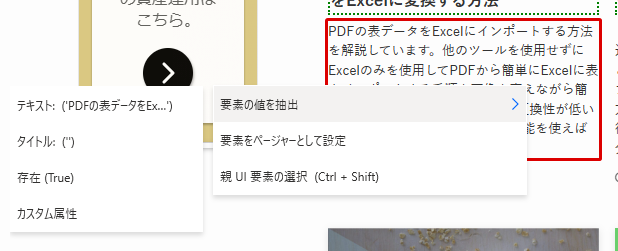
すると今度は、説明文を1つ選択したところで先ほどの手順で取得していたタイトルに紐づいている説明文がライブWebヘルパーに表示されました!

ページャーの設定
上記までの手順で1ページに表示された、タイトルと説明文を抽出することができました。
でもここまで来たら、すべてのページに及ぶ記事一覧のタイトルと説明文を取得したいですよね。
もしもスクレイピングするサイトに「次へ」のようなページャーが存在する場合には、複数のページに及ぶ一覧の情報をすべてのページを網羅してデータを取得することが可能です。
残念ながら、例として使用している当ブログには、「次へ」のようなページャーが存在しないので、参考までに2ページ目までの情報を取得するような手順を解説します。。。
先ほどの続きから、ページ上の「次へ」に当たるページャー部分にカーソルを合わせて、「要素をページャーとして設定」をクリックします。
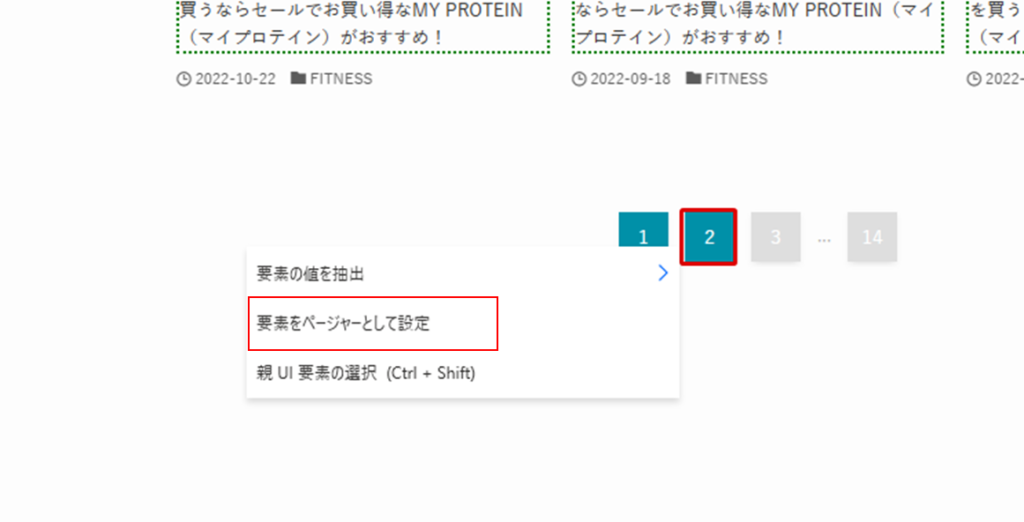
するとライブWebヘルパーに「次のページに対応する値」が表示されます。

このように設定することで、次のページの一覧の情報も取得することができます!
今回の場合は、2ページ目を選択してしまっているので、1、2ページ目までしか取得することができませんが、ちゃんと「次へ」のようなページャーがある場合には、すべての一覧が取得できますので、必要に応じて設定してみてください。
スクレイピング処理の実行
それでは、上記までで作成したフローを実行してみましょう。

以下のようにExcelに記事のタイトルと説明文が一覧として出力されました!
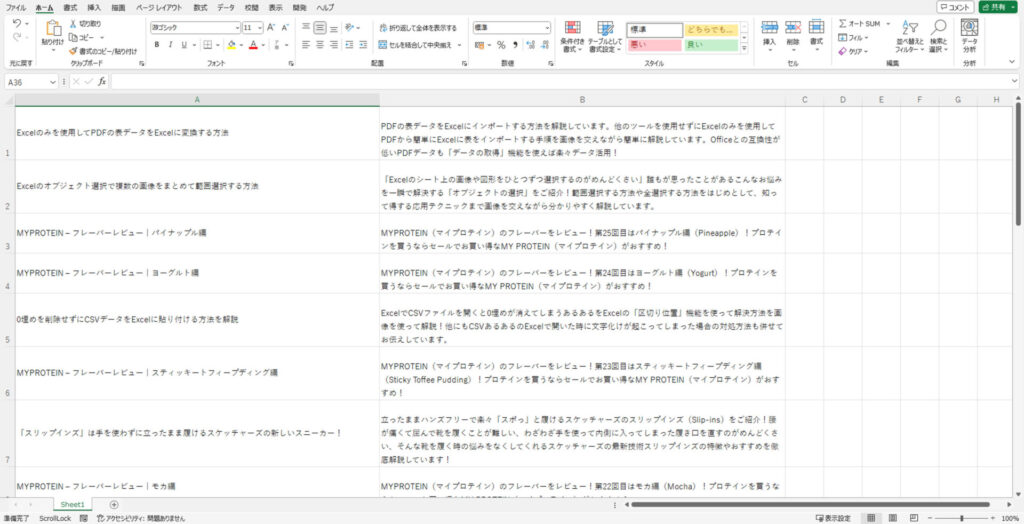
スクレイピングと聞くと難しそうな手順が必要かと思うかもしれませんが、実際にフロー上にある処理としては、2つでここまでのことができてしまいましたね!
まとめ:Power Automateで面倒な情報収集を自動化!
今回は、Power Automate Desktopを使用してデータスクレイピングをする方法を解説いたしました!
活用することができればとても便利なデータスクレイピングですが、サイトによってはロボットによる自動的なページのクローリングを許可していないことがあることは必ず念頭に置いたうえで実施するようにしましょう。
手順よりも規約やルールなどが難しいかもしれませんが、面倒なデータの収集はロボットにまかせて、人間はデータから何が分かるかに集中することで、仕事の効果を最大化することができれば大きな生産性向上につながりそうですね!
当ブログでは、Power Automate以外にも業務効率化に関わる記事を多く紹介しておりますので、興味を持っていただけた方はぜひそちらもご覧ください!
(参考:PC業務効率化に関する記事一覧)




をする方法-300x169.jpg)




コメント